
事件概览:Cloudflare三小时瘫痪,“五分之一互联网”一度掉线
11月18日,全球知名网络基础设施服务商 Cloudflare 出现严重服务中断,导致众多依赖其 CDN 与安全防护的站点出现 500 报错、页面加载失败等问题。
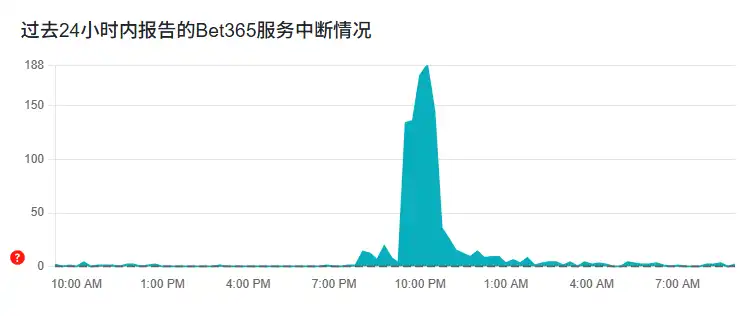
- 根据 Cloudflare 官方博客和状态页面,这次事故在北京时间 11 月 18 日 19:20 左右开始爆发,约在当晚 22:30–22:42 完成修复,峰值影响时间接近三小时。
- 英国媒体披露,Cloudflare 为全球约五分之一的网站提供服务,这意味着一旦出现故障,影响范围将呈指数级放大。
- 本次宕机期间,X、YouTube、ChatGPT、League of Legends 等高流量网站陆续被用户报告“无法访问”或“访问异常”,线上博彩与游戏类平台也在波及之列。
对于高度依赖实时访问与交易的线上博彩行业而言,这种基础设施级别的故障,直接冲击到了投注体验和平台运营的连续性。
bet365无法访问:从“盘口页面”变成“错误提示”
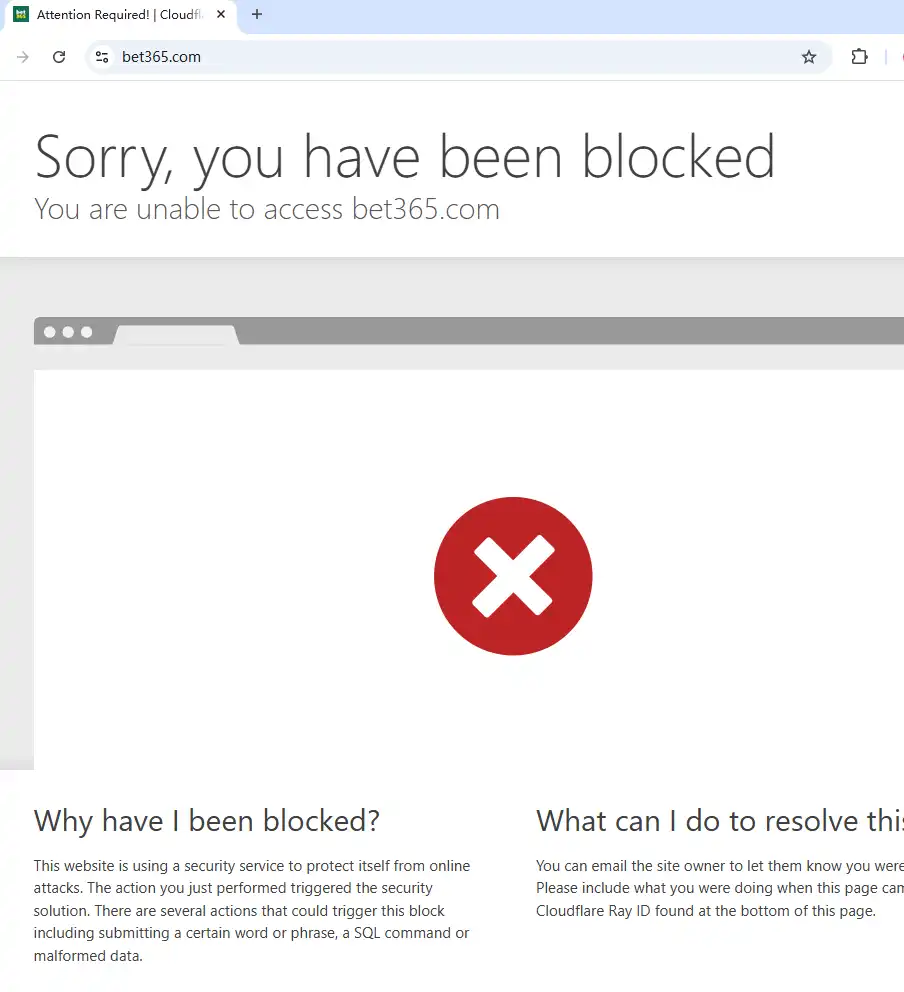
在所有受影响的网站中,体育博彩巨头 bet365 是被多家媒体明确点名的平台之一。

Bet365在200个国家拥有超过3500万客户,全球员工超过5000人。
注意:bet365已退出中国。详见:bet365正式退出中国博彩市场
- 英国媒体引用监测网站数据指出,Cloudflare 故障期间,用户访问 bet365 时大面积出现“内部服务器错误”或 Cloudflare 代理层报错,导致网站在部分地区几乎处于“不可用”状态。
- Downdetector 这样的故障监测平台上,bet365 在 11 月 18 日中午前后突然出现异常报告高峰,其中“网站无法访问”“无法登录”“投注失败”等问题占比较高。
- 有用户反馈,他们看到的并不是熟悉的盘口和赛事列表,而是类似“内部错误”或 Cloudflare 安全挑战页面的信息,说明问题主要出现在 Cloudflare 这一“前置防护层”,而非 bet365 自身后台单独宕机。
从博彩业务角度来看,这种“前端整段时间打不开”的故障,会直接影响到:滚球盘下注、临场赔率调整响应、赛中提前结算等关键环节,对于以实时盘口著称的 bet365 来说尤为敏感。
有公开证据可以确认:
- bet365 在 2019 年 8 月之前,就已经开始使用 Cloudflare 作为前端防护/加速层;
- 之后一直延续到现在(2025 年 11 月),包括这次 11 月 18 日的大规模故障。
其他博彩与相关平台:sweepstakes、加密博彩同样中招
除了 bet365,部分抽奖制(sweepstakes)和加密货币相关的线上博彩平台也被行业报道和监测数据点名受到波及:
- 一些面向北美玩家的 sweepstakes 型博彩站点,在 Cloudflare 故障时段出现访问异常、验证失败或页面加载不全的情况。
- 涉及加密货币支付或加密赌场的国际站点,由于同样依赖 Cloudflare 进行流量加速、防爬和DDoS防护,在此次故障期间也被用户集中举报访问不稳定。
- 行业媒体普遍用“包括多家 iGaming 平台与博彩相关服务在内的大量网站出现访问问题”来描述这次事件,不过除头部平台外,多数中小站点并未被逐一公开点名。
整体来看,凡是前端严重依赖 Cloudflare 作为唯一入口的博彩或游戏站点,这一次几乎都经历了不同程度的访问抖动,只是规模与曝光度有所差异。
故障技术原因:内部配置缺陷,而非网络攻击
值得注意的是,这次 Cloudflare 宕机并非外部攻击,而是“自己绊倒自己”。
- Cloudflare 事后发布技术说明称,事故由一个用于威胁情报和 Bot 管理的自动生成配置文件“体积过大”引发,该文件触发了底层软件缺陷,导致多个关键服务崩溃。
- 这一缺陷在例行配置变更中被激活,进而影响到 Cloudflare 的安全挑战、流量处理等功能,最终表现为大范围 500 错误和代理层失败。
- Cloudflare 强调,没有证据显示事故与DDoS攻击或恶意流量有关,这是一次纯粹的内部软件与配置问题。
对博彩网站来说,这意味着:哪怕自身服务器稳定、数据库正常,只要前面那层 Cloudflare“闸门”失灵,用户依然会觉得“网站挂了”。
对全球线上博彩行业的警示:基础设施集中度过高
这起事故之所以引发广泛讨论,很大一部分原因在于,它暴露出线上博彩行业在基础设施层面的“集中化风险”。
- 很多头部博彩品牌(体育、赌场、扑克乃至彩票)都习惯把 CDN、防火墙、反爬和地理封锁等关键功能外包给少数几家大型服务商,Cloudflare 正是其中影响力最大的玩家之一。
- 对运营方来说,这样做可以快速获得全球加速、防DDoS和Bot管理能力,降低自建成本;但代价是:一旦基础设施提供方出现问题,上游博彩平台在短时间内几乎“无路可走”。
- 从这次事件的表现看,即便 Cloudflare 在数小时内完成修复,对需要 7×24 小时不间断提供投注服务的博彩公司来说,已经足以带来:
- 高峰期投注中断、滚球盘无法正常接单
- 玩家资金与订单状态同步延迟,引发投诉
- 合作方(如数据供应商、联营网站)短时间流量和收入骤降
在全球合规不断收紧、赛事资源和玩家争夺愈发激烈的背景下,一次基础设施层面的“全网掉线”,对品牌口碑和商业数据都会留下实实在在的伤痕。
平台与玩家的启示:冗余架构与风险认知缺一不可
这次 Cloudflare 宕机事件,也给博彩平台经营者和普通玩家提了几条“现实而残酷”的课:
- 对平台方而言:
- 需要认真评估对单一基础设施供应商(如 Cloudflare)的依赖程度,考虑在 DNS、CDN、防护层等关键环节建立冗余方案;
- 在投注系统设计上,对短时网络中断要有更完整的应急机制,比如:明确中断期间投注处理规则、加大缓存与队列容错能力。
- 对玩家而言:
- 在全球化网络架构下,即便是 bet365 这样体量的巨头,也无法完全规避上游供应商的技术故障;
- 遇到短时间“网站打不开”或 500 报错,未必意味着平台资金安全出现问题,更可能是 Cloudflare 一类前端服务“掉链子”;
- 在这种场景下,避免在页面频繁刷新下重复提交订单,是减少异常投注纠纷的基本做法。
可以预见的是,本次 Cloudflare 宕机会成为博彩与更广泛互联网行业的重要“反思样本”:既提醒平台方在技术架构上考虑多云、多CDN和故障转移,也让玩家意识到——博彩体验背后的那套全球基础设施,其实远比看到的盘口和赔率要复杂得多。


























